JspWebShell新姿势解读
写在前面
刚刚无意间发现我yzddmr6发了篇新文章,里面提到了一个jspwebshell的新姿势,但是没有具体分析,那么这里我就接着来分析一波
首先代码长这样
1 | <% |
正文
如果按照传统Java的javac的方式编译这样一定是会出错的,这里不贴图自己试试,而jsp不同于普通的java程序,jsp是有自己的对类编译时的实现机制,其编译类的时候最终是在org.apache.jasper.compiler.JDTCompiler#generateClass生成我们的class文件(省略中途的很多步骤直捣黄龙,不然讲着也费劲)
这是调用栈,有兴趣可以深入分析
1 | getNextToken0:1482, Scanner (org.eclipse.jdt.internal.compiler.parser) |
好了不扯那么多,回到正题,在讲之前我们需要知道有个东西叫javadoc相信大家都很熟悉了就是用于描述方法或者类的作用的东西,而造成可以解析的原因其实和这个有关系(jsp编译过程当中用到了AST,这里不多扯)
在生成最终class的过程当中,它会遍历文件当中的字符并做unicode解码处理,下图可以看到正在遍历的过程
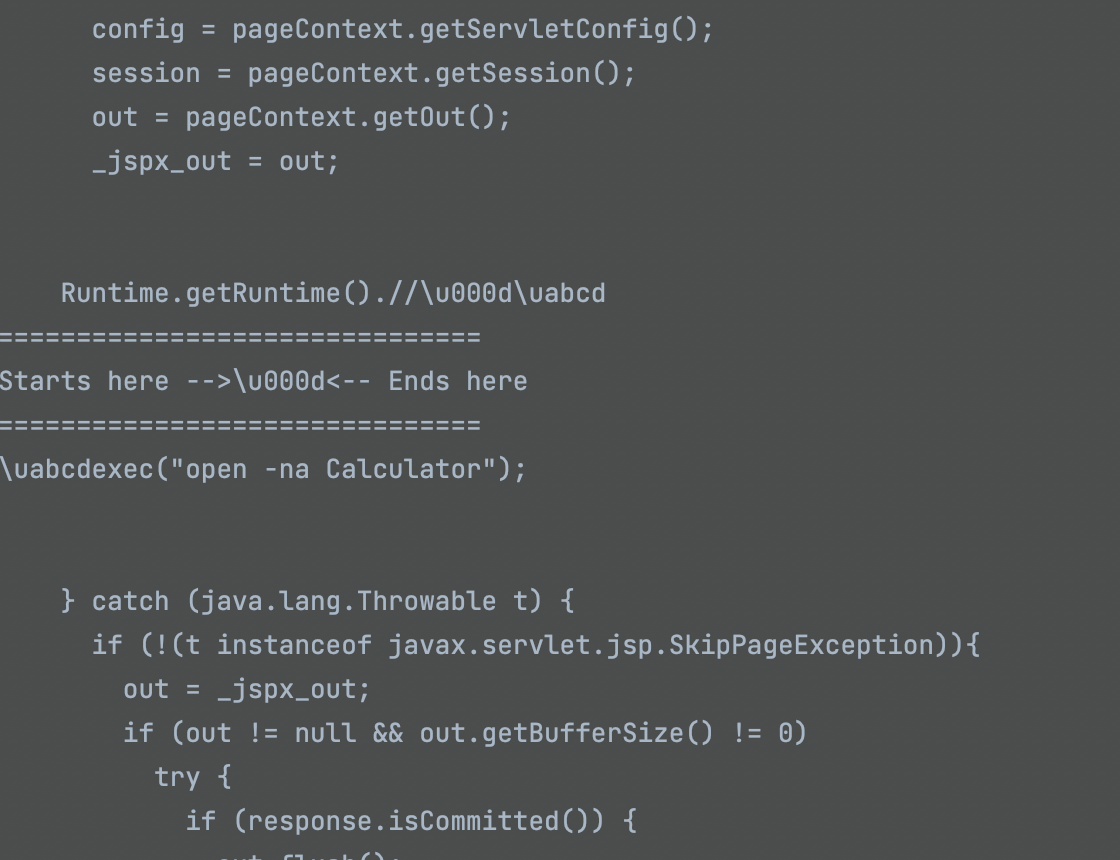
而对于unicode的处理最终在org.eclipse.jdt.internal.compiler.parser.Scanner#getNextToken0,简单看了眼代码其实是为了让AST兼容注释功能,回到代码如果开头是/,之后会判断下一个字符是/还是*,也就是单行或者多行注释咯
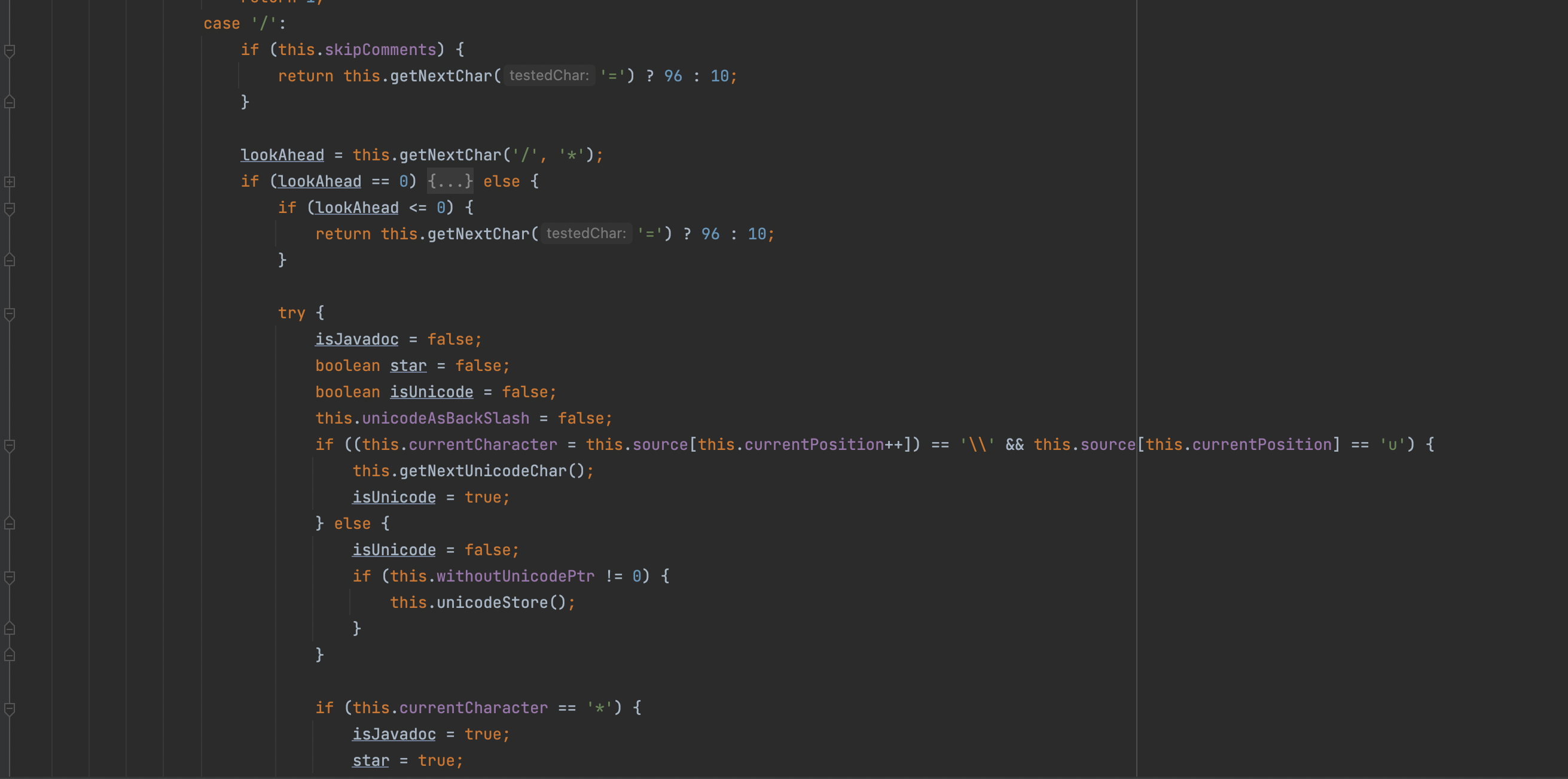
根据代码我们这里显然lookAhead为0,因此我们来看if分支,继续往下走当前为\r如果下一个又是unicode编码的字符会进行unicode解码同时isJavadoc属性会赋值true
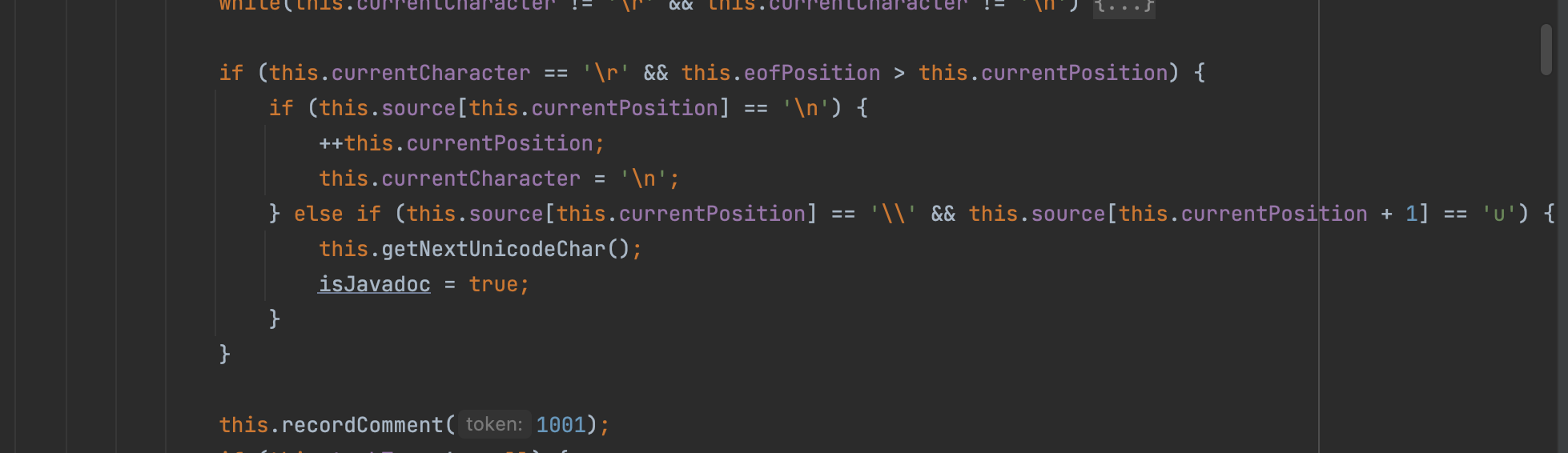
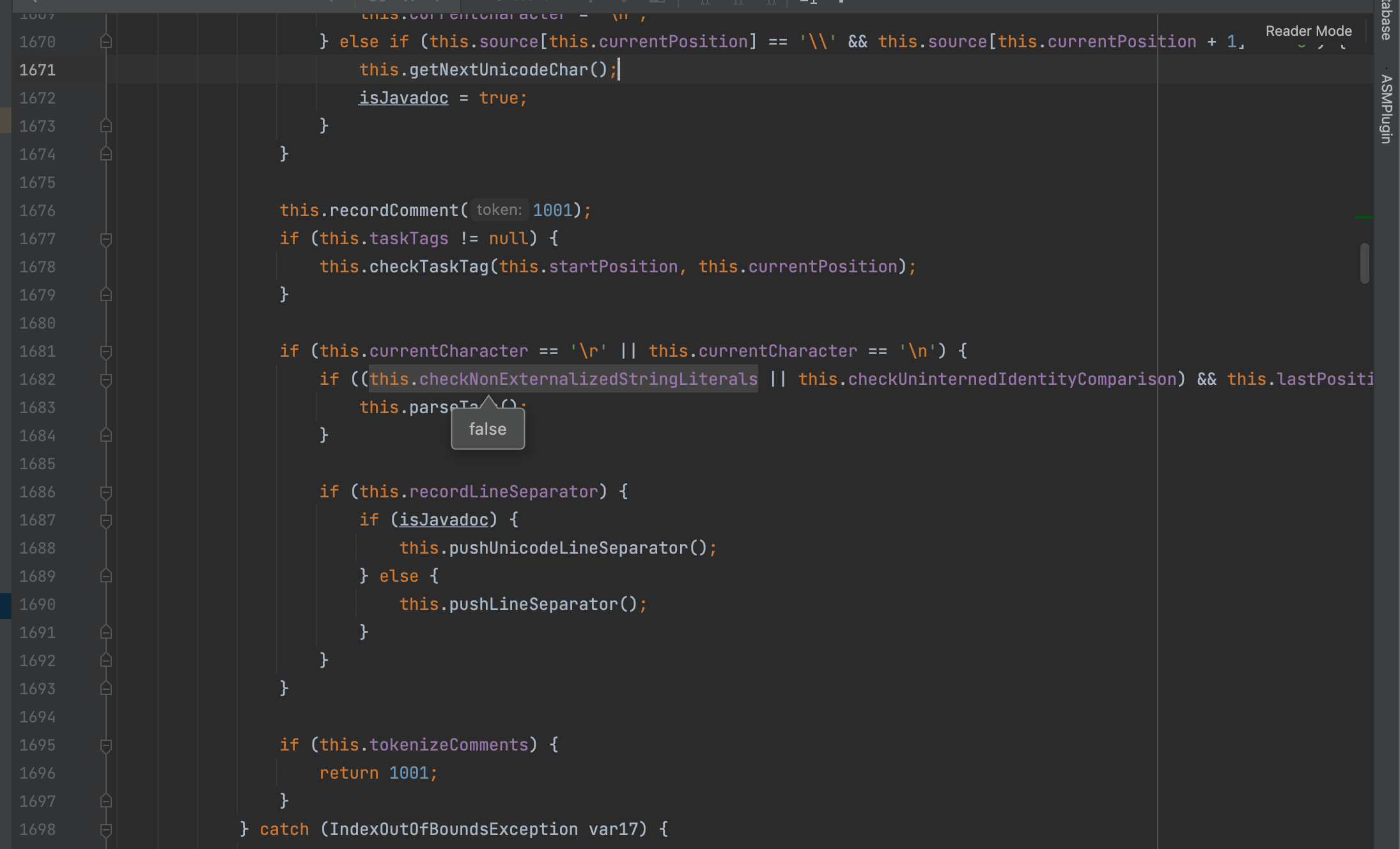
接着往下我们的\uabcd是乱码字符和下面条件也不符合所以也不继续走了简单看看代码呗,不走的原因一方面是这个下一个字符不是\n另一方面checkNonExternalizedStringLiterals在我这个tomcat版本默认为false

但是我还是好奇的看了一眼parseTags函数,在里面处理的注释前缀是TAG_PREFIX = "//$NON-NLS-".toCharArray();,以及IDENTITY_COMPARISON_TAG = "//$IDENTITY-COMPARISON$"很神奇简单考古可以看到https://stackoverflow.com/questions/654037/what-does-non-nls-1-mean,从描述可以看出作用是为了国际化,但更具体的可以看看官方的这篇文章了解写的很详细https://www.eclipse.org/articles/Article-Internationalization/how2I18n.html
当然肯定能在这个层面上做更多的混淆,接下来的灵活的工作就交给大家自己构造了,感谢我yzddmr6,之前还没想到可以这样
但是还是不知道如果默认属性开的情况下,为什么出现//\u000d\u000a或//\u000d\u000d就会判别是要去识别那两个标签,希望有懂的师傅说说